Moving to Web based bulk data loaders
Existing loader users Java and deployed using JNLP
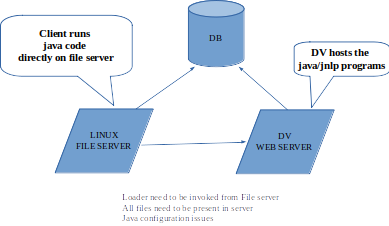
For the new loader, we could further streamline and improve over the earlier loader interface.
Thinking of a uniform workflow for all type of files (all docs, segy, vsp, well logs)
- User select and add all files to be loaded into workspace
- Option to select and associate files with new/existing files, other entities like Survey, Line, Wells etc (Document loader capability)
- File scanning and parsing could be at the client side (using HTML5 file API - Rohit/Vinay already did this?)
- We will have custom file meta dialogs based on the load job/file type
- Bulk file loading could use Jim's nodejs file upload function
Step 3 (file scanning) could be at client or server side. Depending on this, we will have to frame other parts.
- Seismic loader is already split into 2 - GUI and loader
- If parse/load function remains in the server side, only GUI need to be moved to web
- Log/Doc loader can also be split into 2 like this?
- We will need to use JOB queue management to submit/monitor loading jobs in the server side
- After successfully testing, we could extent the QUEUE for DV data downloading as well
File editing is still not possible in HTML5, so our segy editing features need heavy modifications (how to do this?)
Minimal GUI and actual parsing and loading in serve rside
Seismic loader is already split into 2 - GUI and loader. If parse/load function remains in the server side, only GUI need to be moved to web.
Currently seismic loader works like this
- Gui to collect meta
- Create XML or parameter file
- Run a shell script to launch java program that reads XML, copy seismic to destination folder, update DB
- Job log can be read back in gui
Log/Doc loader can also be split into 2 like this? Actual loader can remain in Java, at server side.
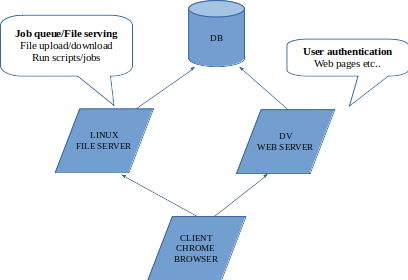
Moving GUI to web
DV server loader module will be the starting point. It can help with user authentication etc..
As you recollect, bulk files like segy are already available (copied from RCC or tapes) in server side.
Let's assume,
- The stage folder is defined in configuration
- We will have a process running (nodejs) in file server to facilitate file loading/downloading etc..
So our flow could be like this.
- Upload files to stage location in file server
- Select and add files in staging area to loader workspace
- Job also will be created/saved in the staging area
- Once the meta info are gathered, java program can run in server to parse the job file, copy file to destination and update database
- We could think of a staging area in database also. Another person can check the data in stage and commit to production (like old systems)
Here our files will be first uploaded to server staging area. Then further editing/meta population happens
While converting from Java to C# or JS, we could think of maximum reusable and abstractions, scalable components/classes
Some references
- https://web.dev/native-file-system/ Chrome supports native file access, will it work for large files? We will have to test it out
- https://developer.chrome.com/apps/about_apps We could develop a web app on this model? WebApps is discontinued in favour of extensions by Gogole/Chrome. So this is not going to last for us.
- NPM/Nodejs/GruntJS in backend (running in file-server) and Bootstrap/HTML/JS/React.js based code in the browser front should be enough for us
- http://www.dba-oracle.com/t_schedule_unix_shell_scripts_using_dbms_scheduler.htm Oracle dbms_scheduler for shell scripts
- https://stackoverflow.com/questions/54205500/how-to-execute-bash-shell-script-in-linux-from-an-oracle-dbms-scheduler Another shell script job schedule
- https://docs.oracle.com/cd/A57673_01/DOC/server/doc/SD273/ch10.htm Job queus in Oracle
- https://myspace.ongc.co.in/blogs/loadv2/?lang=en_us Java job queue with Oracle back-end, simple and light